An Intuitive Explanation of Sparse Autoencoders for LLM Interpretability
Last updated: 2024-11-29
Introduction to Sparse Autoencoders
In the realm of machine learning and artificial intelligence, understanding the inner workings of models, especially large language models (LLMs), has become increasingly important. As these models grow in complexity, so does the need for interpretability. This is where sparse autoencoders come into play, offering a novel approach to unraveling the often opaque mechanisms behind LLMs. The recent Hacker News story titled "An Intuitive Explanation of Sparse Autoencoders for LLM Interpretability" provides a comprehensive dive into this subject, shedding light on how sparse autoencoders can enhance our understanding of LLMs.
What Are Sparse Autoencoders?
Sparse autoencoders are a type of artificial neural network that is designed to automatically learn a representation of input data in a way that encourages sparsity in the learned features. Unlike traditional autoencoders, which aim to reconstruct the input data as closely as possible, sparse autoencoders add a regularization term that penalizes the use of too many active neurons in the hidden layer. This encourages the model to activate only a small number of neurons, leading to a more efficient representation of the input.
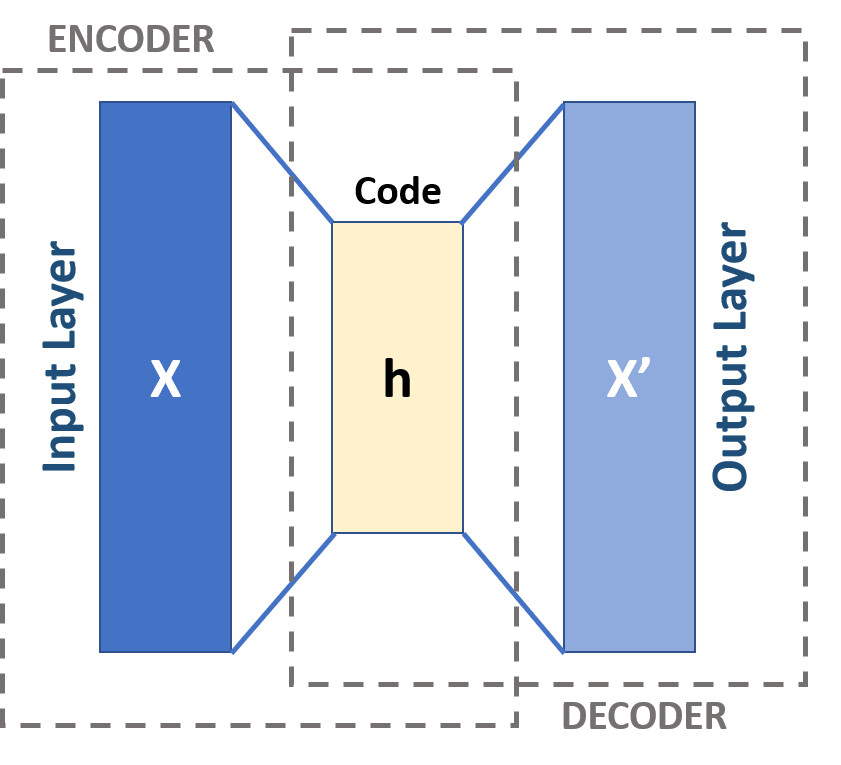
The Mechanics of Sparse Autoencoders
At the core of sparse autoencoders is the idea of forcing the model to find a compact representation of the input data. When an input is fed into the sparse autoencoder, it passes through an encoder that transforms the input into a lower-dimensional space. This hidden representation is then decoded back to the original input space. The loss function includes both the reconstruction loss (how well the output matches the input) and a sparsity penalty, which encourages the network to deactivate most neurons, effectively leading to a more meaningful representation.
Importance of Interpretability in LLMs
Large language models have surged in popularity due to their performance in natural language understanding and generation. However, their black-box nature poses challenges for interpretability. As these models are deployed in sensitive applications, such as healthcare and justice, stakeholders are demanding more transparency about how decisions are made. By utilizing techniques like sparse autoencoders, researchers aim to peel back the layers of complexity to make the internal workings of LLMs more understandable.
How Sparse Autoencoders Contribute to LLM Interpretability
1. Feature Extraction: Sparse autoencoders can identify key characteristics of the input data, which helps in understanding what features the LLM focuses on during its processing. This can demystify how the model weighs different aspects of the input when generating responses.
2. Noise Reduction: By learning a compact representation, sparse autoencoders help filter out irrelevant noise from the input data. This focuses the model's attention on significant patterns, allowing researchers to see which features are truly driving the model's outputs.
3. Visualization: The sparse representations created by the autoencoders can be visualized, providing an intuitive understanding of how different inputs activate various parts of the model. For instance, this could reveal which neurons respond to specific linguistic constructs, aiding in interpreting model behaviors.
Real-World Applications of Sparse Autoencoders in LLMs
The application of sparse autoencoders goes beyond mere academic interest. They have practical implications in various sectors:
1. Finance: In fraud detection models, understanding why a transaction is flagged as suspicious is crucial for mitigating risks. Sparse autoencoders can clarify which patterns of behavior led to a model's decision, allowing for preemptive action.
2. Healthcare: With diagnostic models, knowing how a certain input influences the model's conclusion can be the difference between proper treatment and oversight. Sparse representations can highlight critical features in patient data that inform diagnosis.
3. Legal Systems: The transparency required in legal decisions is paramount. Using sparse autoencoders can help explain how certain data points were interpreted by a model used in predictive policing or risk assessment tools, ultimately leading to more accountable AI systems.
Challenges and Future Directions
While sparse autoencoders offer promising avenues for interpretability, there are challenges to consider:
1. Model Complexity: As the architectures of LLMs become more sophisticated, integrating sparse autoencoders may introduce additional layers of complexity that could hinder performance or complicate the training process.
2. Generalization: Ensuring that the insights gained from sparse autoencoders are applicable across various datasets and tasks remains a challenge. More research is needed to understand the generalizability of the features learned.
3. Balancing Sparsity and Performance: Too much sparsity may lead to a loss of important information, adversely affecting model performance. Striking the right balance between interpretability and accuracy is an ongoing area of exploration.
Conclusion
Sparse autoencoders represent a significant step forward in making the enigmatic workings of large language models more understandable. By encouraging the discovery of compact representations of input data, they pave the way for greater interpretability, which is essential in high-stakes applications. As researchers continue to build on these concepts, we can expect to see advancements that not only enhance our interpretive capabilities but also enforce ethical practices in deploying AI technologies.
For a deeper dive into the topic, be sure to check out the Hacker News discussion regarding An Intuitive Explanation of Sparse Autoencoders for LLM Interpretability.