Chain of Continous Thoughts Might Enhance Reasoning in LLMs
Last updated: 2024-12-11
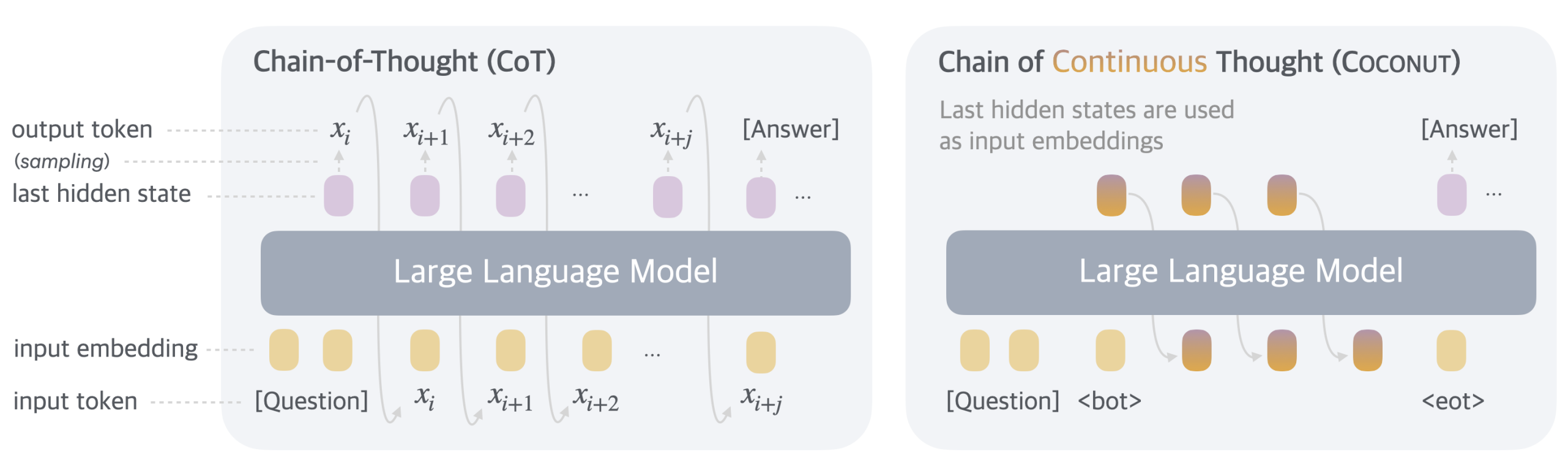
In the realm of artificial intelligence, particularly in the domain of language models, the evolution of techniques to enhance reasoning capabilities has been pivotal. Researchers at Meta and UC San Diego published "Training LLMs to Reason in a Continuous Latent Space" - proposing an innovative approach to training Large Language Models (LLMs) that utilizes a continuous latent space to improve reasoning processes. In this post, we will explore the concepts presented in the article, discuss the implications for the future of AI, and delve into how this new training paradigm could shape more sophisticated LLMs.
The Problem with Current LLMs
Current LLMs, such as OpenAI's GPT, have transformed our interactions with machines, providing unprecedented capabilities for text generation, comprehension, and even engagement in dialogue. However, a common critique of these models is their limited reasoning ability. While they can generate human-like text, their understanding of context, logic, and causation often falls short in complex scenarios.
One major limitation lies in how these models represent knowledge. Traditional methods often rely on discrete latent spaces, which can restrict the way information is encoded and understood, leading to challenges in reasoning tasks. This is where the notion of a continuous latent space comes into play, as proposed in the Hacker News article.
Understanding Continuous Latent Spaces
A continuous latent space allows for a more fluid representation of knowledge. In contrast to discrete spaces that categorize information into fixed slots, continuous spaces can accommodate more variability and nuance. This allows models to approximate complex relationships and nuances in data more effectively.
In a continuous latent space, information is represented as points in a higher-dimensional space, enabling smoother transitions between different states of knowledge. This approach could potentially enhance LLMs' ability to reason by allowing them to explore a broader spectrum of possibilities and connections when making inferences or decisions.
Key Innovations Proposed
The article discusses several innovative techniques for training LLMs within a continuous latent space framework. Here are some key takeaways:
1. Dynamic Encoding of Knowledge
Rather than static representations, the training process emphasizes dynamic encoding, where models can continuously update their understanding based on new inputs and experiences. This adaptability can improve the model’s ability to respond to novel situations and reasoning challenges.
2. Enhanced Contextual Awareness
By leveraging a continuous latent space, models may achieve a better contextual grasp of the text they process. This is crucial in reasoning tasks that require understanding subtleties and implicit meanings that go beyond the explicit content of the text.
3. Improved Transfer Learning
Continuous latent representations can facilitate more effective transfer learning, enabling models trained on one task to apply knowledge and reasoning skills to seemingly unrelated tasks. This could lead to more generalizable models capable of operating in diverse scenarios.
Implications for AI Development
The advancements in training LLMs to reason within a continuous latent space carry significant implications for the broader field of artificial intelligence:
1. Advancing Human-Computer Interaction
Improved reasoning capabilities in LLMs can lead to more natural interactions between humans and machines. As models become better at understanding context, users may find it easier to communicate with AI systems in a more conversational manner.
2. Applications Across Domains
From healthcare to education, improved reasoning in LLMs opens doors for more sophisticated applications. For instance, in healthcare, LLMs could assist in diagnostics and treatment recommendations by contextualizing patient histories and presenting plausible scenarios based on continuous input.
3. Ethical Considerations
As AI systems become increasingly proficient at reasoning, it raises questions about their ethical use. Understanding how these models make decisions and reason through complex scenarios will become imperative to ensure accountability and trust in AI systems.
Challenges Ahead
While the concept of training LLMs in a continuous latent space is promising, there are challenges to address:
1. Computational Complexity
Implementing continuous latent spaces increases the computational burden on models. Training such models necessitates significant resources, which may limit their accessibility and feasibility for broader applications.
2. Interpretability
As with many advancements in AI, ensuring that these reasoning models are interpretable remains a critical challenge. Users need to understand how decisions are made by AI systems, particularly in high-stakes scenarios where reasoning plays a crucial role.
Conclusion
The approach of training LLMs to reason in a continuous latent space represents a significant step forward in AI research. It seeks to bridge the gap between mere text generation and genuine understanding, which is fundamental for developing more autonomous and intelligent systems. As this technology evolves, we will likely witness a transformation in our capabilities to deploy LLMs in more meaningful and impactful ways across various sectors.
As we move forward, continued exploration and research will be essential to refine these methodologies, address the challenges posed, and ultimately create models that can engage with us not just as tools, but as intelligent partners in problem-solving and decision-making.